Intelligence artificielle
28 mars 2026
Sources des données et méthodologie
Lire la suite


Développement et validation d'un modèle accessible d'âge biologique à plusieurs niveaux pour la santé de la population


Auteur principal : Serene TOH, BSc. — Responsable mondiale des sciences des données et de la modélisation, Elfie Inc.
Auteur correspondant : Jean-François LEGOURD, MSc. — Directeur produit, Elfie Inc.
Affiliations :
Elfie Inc., Division mondiale des sciences des données sur la santé
Les modèles actuelsd'âge biologique ne parviennent souvent pas à communiquer les risques de manière compréhensible et exploitable pour le grand public. Une mesure holistique intégrant les facteurs liés au mode de vie, à la physiologie et aux biomarqueurs est nécessaire pour motiver la prévention. À partir des données sur la mortalité issues de l'enquête NHANES, nous avons développé et validé un indicateur d'« âge biologique » compréhensible, dérivé de données comportementales, anthropométriques et biomarqueurs, et adaptable à différents contextes avec des disponibilités de données variables.
Nous avons analysé les données NHANES 2005-2009 en les reliant à la mortalité jusqu'en 2019 (Centers for Disease Control and Prevention [CDC], 2025). Les adultes âgés de 20 ans ou plus pour lesquels des données complètes sur les facteurs de risque comportementaux, physiologiques et biochimiques étaient disponibles ont été inclus. Des modèles de risques proportionnels de Cox pondérés par enquête ont estimé les associations avec la mortalité non accidentelle, en tenant compte de la complexité du plan d'échantillonnage (Cox, 1972 ; Lumley, 2004 ; Therneau & Grambsch, 2000). Les associations non linéaires ont été évaluées à l'aide de splines cubiques naturelles (Wood, 2017) ; les modèles finaux ont conservé des formes linéaires pour la plupart des variables. Les modèles simplifiés et complets ont tous deux démontré une forte discrimination et un bon calibrage lorsqu'ils ont été validés dans le NHANES 2010-2011.
Le modèle complet comprenait la glycémie (HbA1c), l'eGFR, la pression artérielle, le tabagisme, les heures de sommeil, la dépense métabolique totale par semaine, les antécédents de maladies cardiaques, le sexe et l'âge (échantillon analytique : 7 775 adultes ; 1 106 décès). La glycémie, le nombre moyen d'heures de sommeil, le tabagisme et l'âge étaient des facteurs prédictifs significatifs ; le cholestérol LDL ne présentait aucune association indépendante. Pour pallier l'absence de biomarqueurs, nous avons également estimé un modèle simplifié comprenant uniquement l'âge, le sexe, le tabagisme, le nombre moyen d'heures de sommeil, la dépense métabolique totale par semaine et les antécédents de maladies cardiaques (n = 14 387 ; 2 164 décès). La discrimination est restée forte. Les deux modèles ont été validés en externe avec NHANES 2010-2011 : le modèle complet a atteint une concordance de 0,870, avec une pente d'étalonnage d'environ 1,03 ; le modèle simplifié a atteint une concordance de 0,858, avec une pente d'environ 1,03. L'âge biologique était un facteur prédictif fort de la mortalité (HR par an ≈1,09-1,11).
Une mesure de l'âge biologique peut être dérivée soit d'un modèle riche en biomarqueurs, soit d'un modèle minimal utilisant uniquement des variables facilement disponibles. Une validation externe confirme sa généralisation. Le cadre à deux niveaux équilibre précision et faisabilité, ce qui facilite son utilisation dans le domaine de la santé publique, du conseil aux patients ou de la surveillance sanitaire.
L'âge chronologique est un indicateur fondamental en épidémiologie et en pratique clinique, mais il ne permet pas de saisir pleinement l'hétérogénéité des risques biologiques. Deux personnes âgées de 60 ans peuvent avoir des trajectoires de morbidité et de mortalité très différentes en fonction de leur mode de vie, de leurs comorbidités et de leur biologie sous-jacente. Le concept d'« âge biologique » vise à rendre compte de cette divergence en regroupant plusieurs facteurs de risque en un seul indicateur qui reflète plus fidèlement l'état physiologique de l'individu (Klemera & Doubal, 2006 ; Levine, 2013 ; Liu et al., 2018).
De nombreux modèles existants d'âge biologique, tels que les horloges épigénétiques, les indices de fragilité et les indices composites de biomarqueurs, nécessitent des panels de biomarqueurs étendus ou produisent des résultats qui sont des scores de risque abstraits plutôt que des estimations intuitives de l'« âge » (Levine, 2013 ; Liu et al., 2018). Pour la santé publique et la communication clinique, l'interprétabilité et l'évolutivité sont essentielles (Ganna & Ingelsson, 2015).
Nous proposons un cadre à deux niveaux pour l'âge biologique : un modèle complet qui intègre les mesures des biomarqueurs lorsqu'elles sont disponibles, et un modèle simplifié qui repose uniquement sur des variables faciles à obtenir (âge, sexe, IMC, antécédents médicaux et variables liées au mode de vie telles que le nombre moyen d'heures de sommeil, l'activité physique, le tabagisme et la consommation d'alcool). À partir des données NHANES 2005-2009 associées aux résultats de mortalité à long terme (CDC, 2025), nous avons développé les deux modèles, dérivé une mesure de l'âge biologique en mettant à l'échelle les coefficients de régression de Cox par rapport au coefficient d'âge (Klemera & Doubal, 2006), puis validé les deux dans une cohorte NHANES 2010-2011 distincte. Notre objectif : produire une mesure de l'âge biologique robuste, interprétable et généralisable, adaptée à une utilisation à grande échelle.
Nous avons analysé les données issues de l'enquête nationale sur la santé et la nutrition (National Health and Nutrition Examination Survey), une enquête représentative à l'échelle nationale menée auprès de la population civile américaine non institutionnalisée par le Centre national des statistiques sanitaires (National Center for Health Statistics, NCHS) et les Centres pour le contrôle et la prévention des maladies (Centers for Disease Control and Prevention, CDC, 2025). Le NHANES a recueilli des informations au moyen d'entretiens structurés, d'examens physiques et de tests de laboratoire réalisés dans des centres d'examen mobiles, dont les protocoles détaillés sont publiés ailleurs [CDC, 2025 ; https://www.cdc.gov/nchs/nhanes/index.htm].
Après exclusions, dans l'enquête NHANES 2005-2009, l'échantillon analytique complet comprenait 7 775 adultes (1 106 décès), et le modèle simplifié comptait 14 387 adultes (2 164 décès). Dans la cohorte de validation, les tailles des échantillons étaient plus petites.
Tous les protocoles NHANES ont été approuvés par le comité d'éthique de la recherche du NCHS, et tous les participants ont donné leur consentement éclairé par écrit. Les données analytiques utilisées ici sont anonymisées et accessibles au public.
Le suivi de la mortalité a été assuré grâce à un lien avec le National Death Index (NDI) jusqu'au 31 décembre 2019, tel que fourni par le NCHS. La mortalité toutes causes confondues (non accidentelle) était le critère d'évaluation principal. La durée du suivi correspondait au nombre de mois entre l'examen et le décès ou était censurée en décembre 2019. Les données sur les causes de décès ont été utilisées pour exclure les décès accidentels ; les autres cas de mortalité reflètent le risque de mortalité lié à l'âge.
Toutes les analyses ont intégré le plan d'échantillonnage complexe utilisant des pondérations d'enquête, des strates et des unités d'échantillonnage primaires, garantissant ainsi des estimations représentatives à l'échelle nationale (Lumley, 2004, 2023). Les variables continues ont été exprimées sous forme de moyennes (±SD) et les variables catégorielles sous forme de pourcentages pondérés, tableaux supplémentaires S1 et S2.
La durée de survie a été définie comme le nombre de mois écoulés entre l'examen initial et le décès ou la censure au 31 décembre 2019. La mortalité non accidentelle a été modélisée à l'aide d'une régression des risques proportionnels de Cox pondérée par enquête, svycoxph dans R (Cox, 1972 ; Therneau & Grambsch, 2000). Les prédicteurs candidats comprenaient l'âge, le sexe, le tabagisme, la dépense métabolique totale par semaine, le nombre moyen d'heures de sommeil par jour, la pression artérielle systolique (PAS), la pression artérielle diastolique (PAD), la glycémie (HbA1c), l'eGFR et les antécédents autodéclarés de diabète et de maladies cardiaques. L'indice de masse corporelle (IMC), la consommation moyenne d'alcool, le cholestérol des lipoprotéines de basse densité (LDL-C), le cholestérol des lipoprotéines de haute densité (HDL-C), les triglycérides et la protéine C-réactive (CRP) ont été évalués, mais exclus des modèles finaux en raison de l'absence d'association indépendante avec la mortalité.
Les relations non linéaires ont été évaluées à l'aide des résidus de Martingale et des tests χ² de Wald des termes splines (Therneau & Grambsch, 2000 ; Wood, 2017 ; Royston & Sauerbrei, 2007), figure supplémentaire S3 et tableau S4. Bien que l'âge ait démontré une forte preuve statistique de non-linéarité, nous avons conservé une spécification linéaire pour l'âge chronologique afin de permettre le calcul d'une mesure de risque équivalente à l'âge interprétable (âge biologique). Les termes splines non linéaires ont été conservés pour la glycémie, ce qui a amélioré l'ajustement du modèle sans affecter son interprétabilité. Les nœuds ont été placés aux percentiles pondérés par l'enquête, par exemple HbA1c à [35e, 65e].
Dans la pratique, la plupart des covariables ont affiché un comportement quasi linéaire ; des termes splines simplifiés (df = 1–2) n'ont été utilisés que lorsque les diagnostics confirmaient fortement la non-linéarité.
L'hypothèse de risques proportionnels a été évaluée à l'aide des résidus de Schoenfeld (Therneau & Grambsch, 2000), tableau supplémentaire S6. Aucune violation n'a été observée pour le modèle complet, tandis que pour le modèle simplifié, l'âge, le sexe, le tabagisme, le sommeil ou les antécédents de maladies cardiaques ne présentaient aucune violation, l'activité physique (kcal_kg_semaine) montrait des signes de risques non proportionnels (p = 0,008), bien que l'effet ait été modeste et que le modèle global ait montré une bonne discrimination et un bon calibrage. Étant donné que l'activité n'était pas l'objet principal, nous avons conservé la forme linéaire simple et avons noté cela comme une limitation.
Variance inflation factors (VIFs), supplementary table S7, were below 5 for all variables except the spline terms for sugar intake, which showed VIFs between 7.9 and 9.6. This is expected because spline basis functions are mathematically correlated with each other and does not indicate problematic multicollinearity (Wood, 2017). Pairwise correlations among non-spline predictors were all <0.4, suggesting no evidence of collinearity that would bias estimates or impair model stability.
À partir de chaque modèle ajusté (simple et complet), nous avons extrait les coefficientsβi. La contribution au risque de mortalité de tous les prédicteurs, à l'exception de l'âge chronologique, a été additionnée pour obtenir un score de risque. L'âge biologique de l'individu i a été calculé en mettant à l'échelle les coefficients par rapport à l'âge chronologique (Klemera & Doubal, 2006 ; Levine, 2013) :
BioAgei = Agei + jagejXijage
Pour les modèles où l'âge a été modélisé à l'aide de splines, nous avons utilisé des méthodes d'inversion numérique (c'est-à-dire en calculant la valeur d'âge qui équivaut au prédicteur linéaire complet) afin de maintenir la cohérence.
Nous avons appliqué les coefficients fixes des modèles NHANES 2005-2009 à l'ensemble de données de validation afin de calculer les scores de risque individuels et l'âge biologique. La validation a utilisé l'indice C de Harrell et la pente d'étalonnage pour évaluer la discrimination et l'étalonnage (Harrell et al., 1996) ainsi que les courbes de survie de Kaplan-Meier stratifiées par quartiles d'âge biologique.
All analyses were conducted in R 4.5.1 (R Core Team, 2024), using the survey, survival, and splines packages. Two-sided p-values <0.05 were considered statistically significant.
Figure 1. Flux des participants pour les ensembles de données de développement et de validation
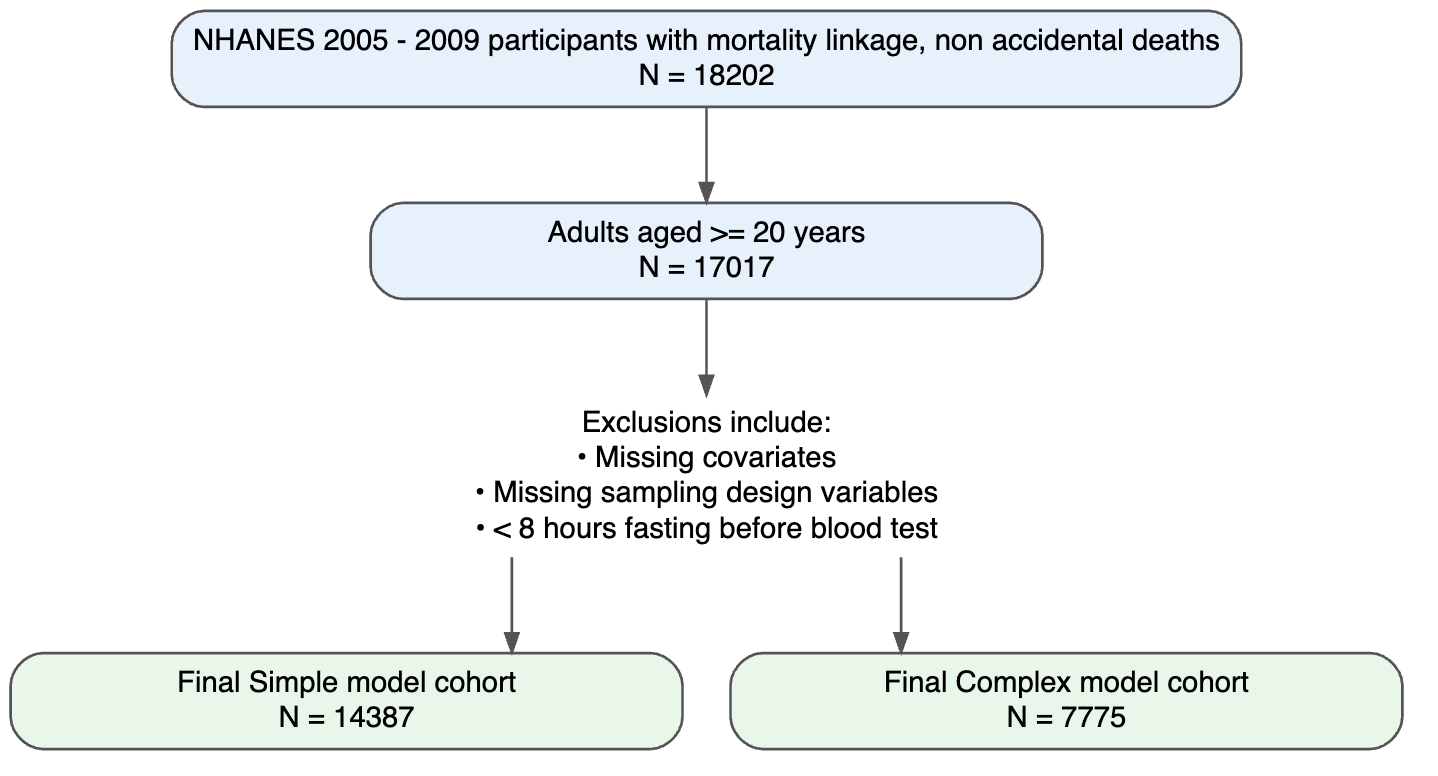
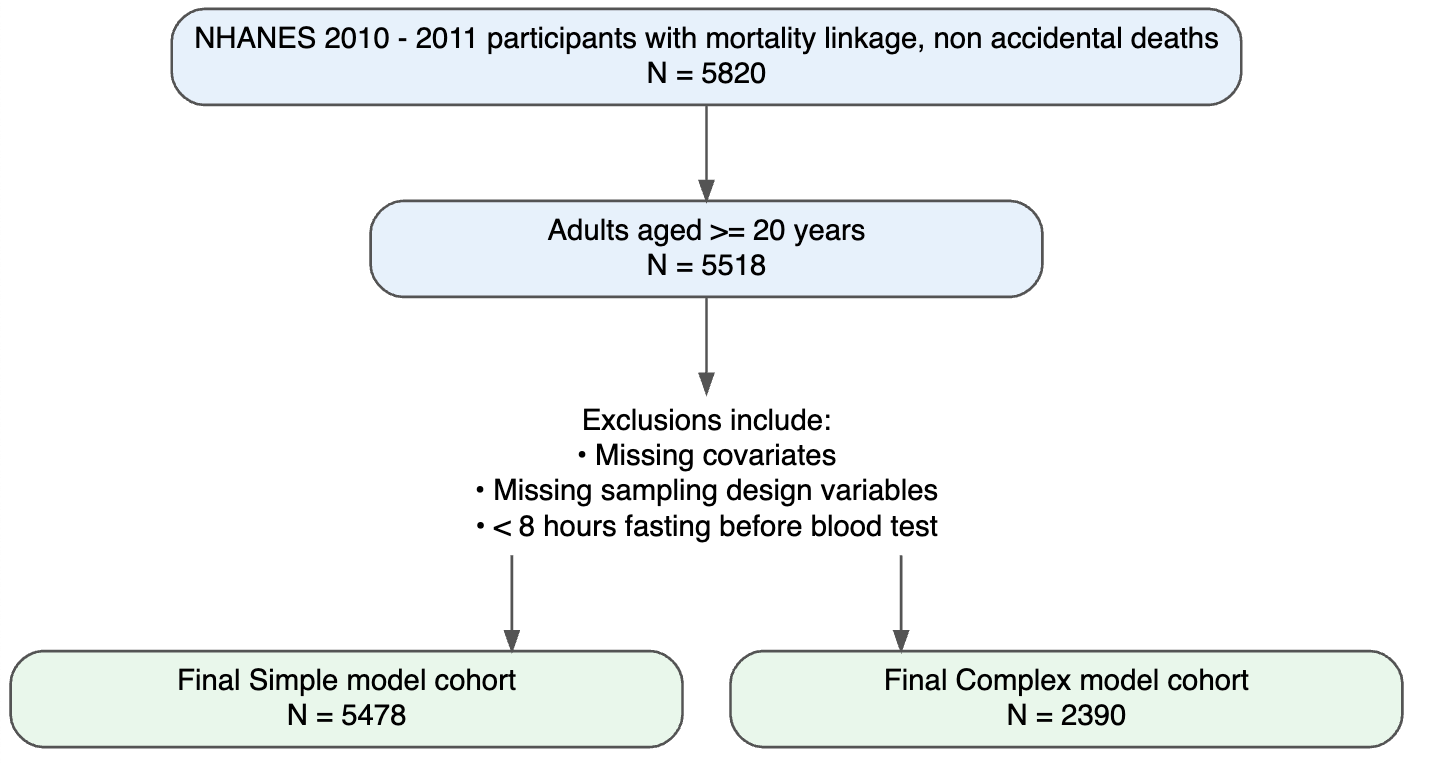
Les caractéristiques de base des participants aux enquêtes NHANES 2005-2009 et NHANES 2010-2011 sont présentées respectivement dans les tableaux supplémentaires 1 et 2. Dans l'ensemble, l'échantillon de validation est plus âgé, présente un eGRF et une dépense métabolique totale hebdomadaire plus élevés, mais les distributions de toutes les autres covariables étaient globalement comparables.
Au cours d'un suivi médian de 11 ans (IQR 9,67 - 12,42), un total de 6 844 décès ont été enregistrés parmi les 16 878 participants inclus dans le modèle simplifié, et 1 106 décès parmi les 7 7775 participants inclus dans le modèle analytique complet qui nécessitait des données sur les biomarqueurs.
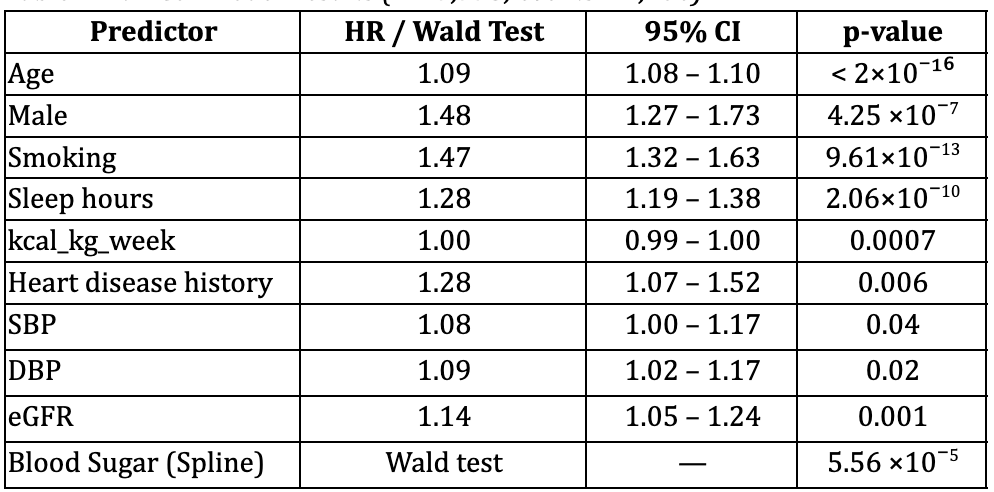
Dans le modèle incluant l'âge, le sexe, le tabagisme, le nombre moyen d'heures de sommeil par jour, la dépense métabolique totale par semaine et les antécédents de maladies cardiaques, tous les facteurs prédictifs étaient significativement associés au risque de mortalité (tableau 1).
Ce modèle a démontré une excellente discrimination, avec un coefficient de concordance de 0,87 (SE 0,005).
Tableau 1. Résultats du modèle de Cox simplifié (n = 14 387 ; événements = 2 164)
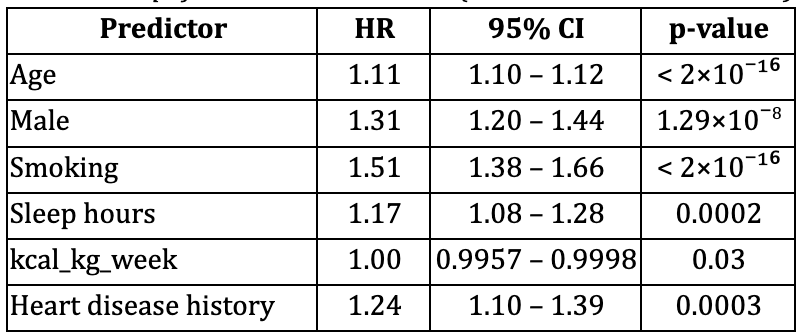
Concordance (statistique C) = 0,87 (SE 0,005)
Modèle analytique complet (y compris les biomarqueurs avec splines) :
Le modèle complet intégrait des termes splines pour la glycémie (HbA1c) et présentait une non-linéarité significative (Royston & Sauerbrei, 2007), tableau 2.
Ce modèle a démontré une excellente discrimination, avec un coefficient de concordance de 0,873 (SE 0,007). Les tests de Wald ont confirmé de forts écarts par rapport à la linéarité pour la glycémie (voir tableau supplémentaire 3).
Tableau 2. Résultats complets du modèle de Cox (n = 7 775 ; événements = 1 106)
Concordance (statistique C) = 0,873 (SE 0,007)
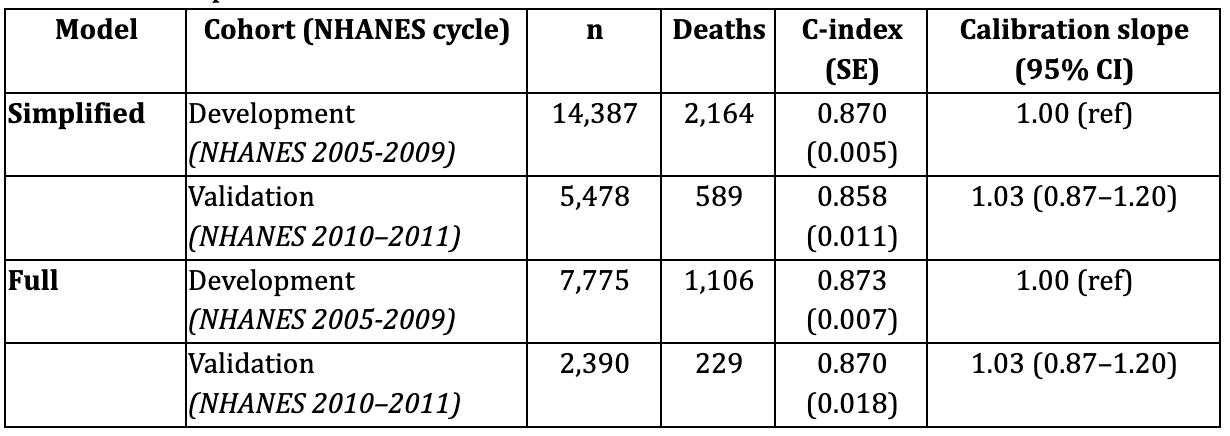
du modèle simplifiéDans la cohorte externe de validation NHANES 2010-2011 (n = 5 478 ; 589 décès), le modèle de risque simplifié a continué à afficher de solides performances prédictives. La discrimination du modèle est restée excellente, avec un indice C de 0,858 (SE ≈ 0,011). L'analyse d'étalonnage a montré une pente de 1,03 (IC à 95 % : 0,87-1,20), indiquant une bonne concordance entre les risques prédits et observés. La stratification des risques à l'aide des tertiles de risque prédit a permis d'obtenir une séparation claire des probabilités de survie à 5 ans (risque faible : 99,6 %, risque moyen : 98,7 %, risque élevé : 89,1 %).
complète du modèleDans la cohorte de validation riche en biomarqueurs (NHANES 2010-2011 ; n = 2 390 ; 229 décès), le modèle complet basé sur des splines a également permis de prédire de manière fiable la mortalité. La discrimination était forte, avec un indice C de 0,870 (SE ≈ 0,018). L'étalonnage était proche de l'idéal (pente = 1,03, IC à 95 % : 0,87-1,20). Les courbes de Kaplan-Meier pour les groupes de risque prédit ont montré une séparation graduelle et monotone, confirmant la stabilité du modèle.
Tableau 3. Performances du modèle dans les cohortes de dérivation et de validation
Résumé
Les modèles simplifié et complet d'âge biologique ont tous deux démontré une excellente discrimination et un calibrage satisfaisant dans la cohorte indépendante NHANES 2010-2011, confirmant leur robustesse et leur généralisation.
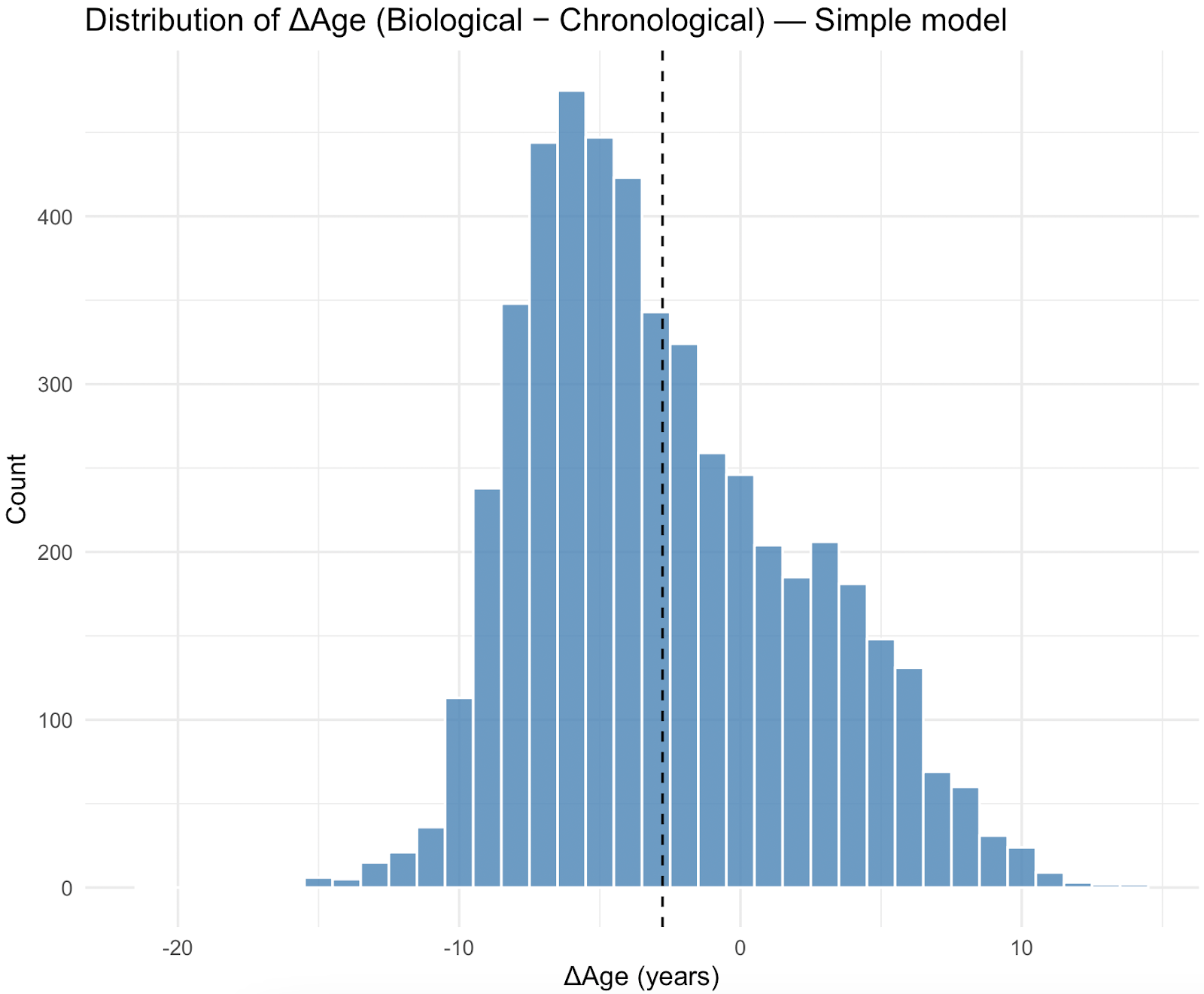
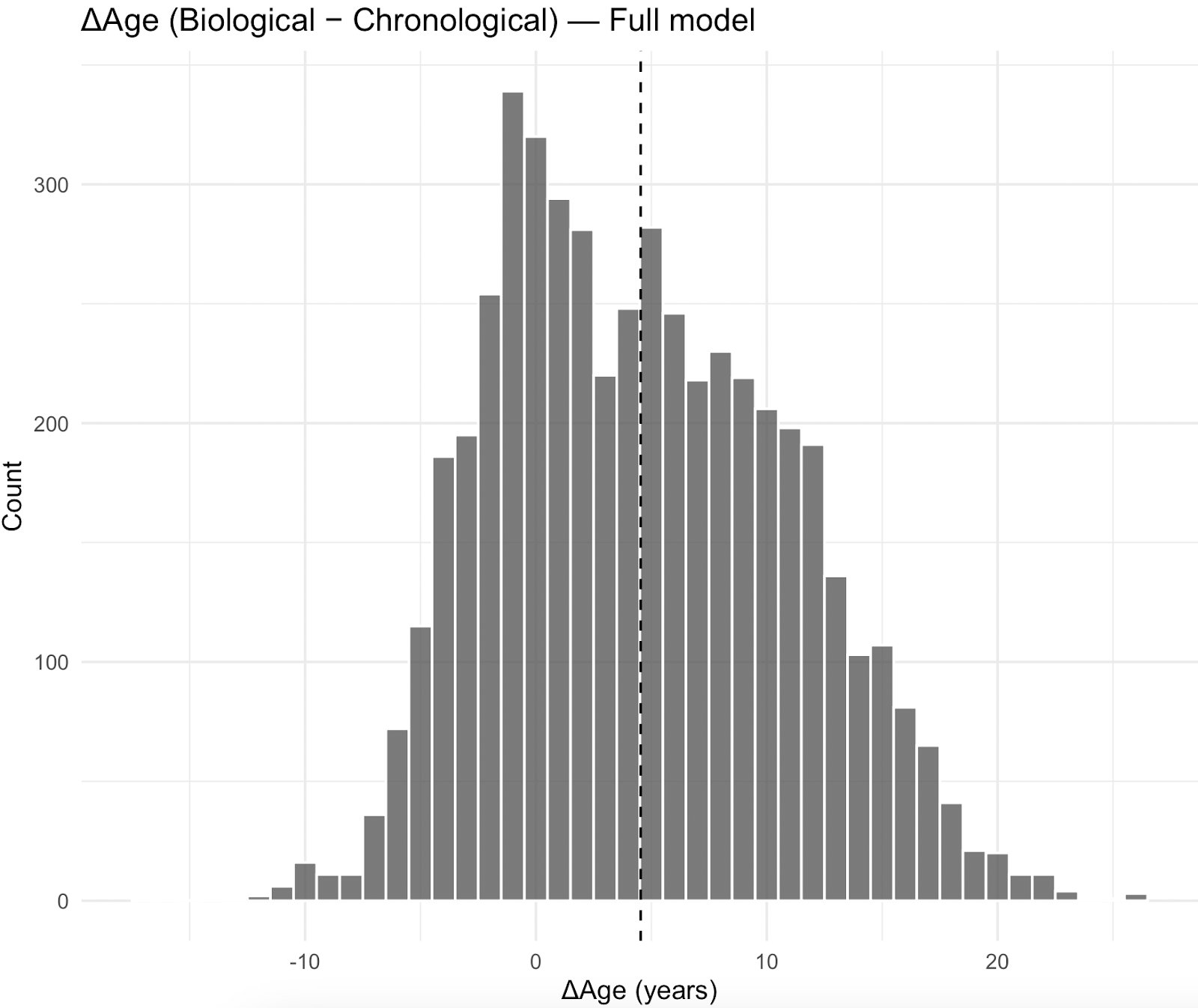
La distribution de l'âge biologique par rapport à l'âge chronologique (ΔAge) était plus négative pour le modèle simplifié, avec une différence moyenne de -2,98 ans (écart-type 4,82), tandis que le modèle complet présentait une différence moyenne de 4,09 ans (écart-type 6,22), estimée à partir des pondérations de l'enquête NHANES.
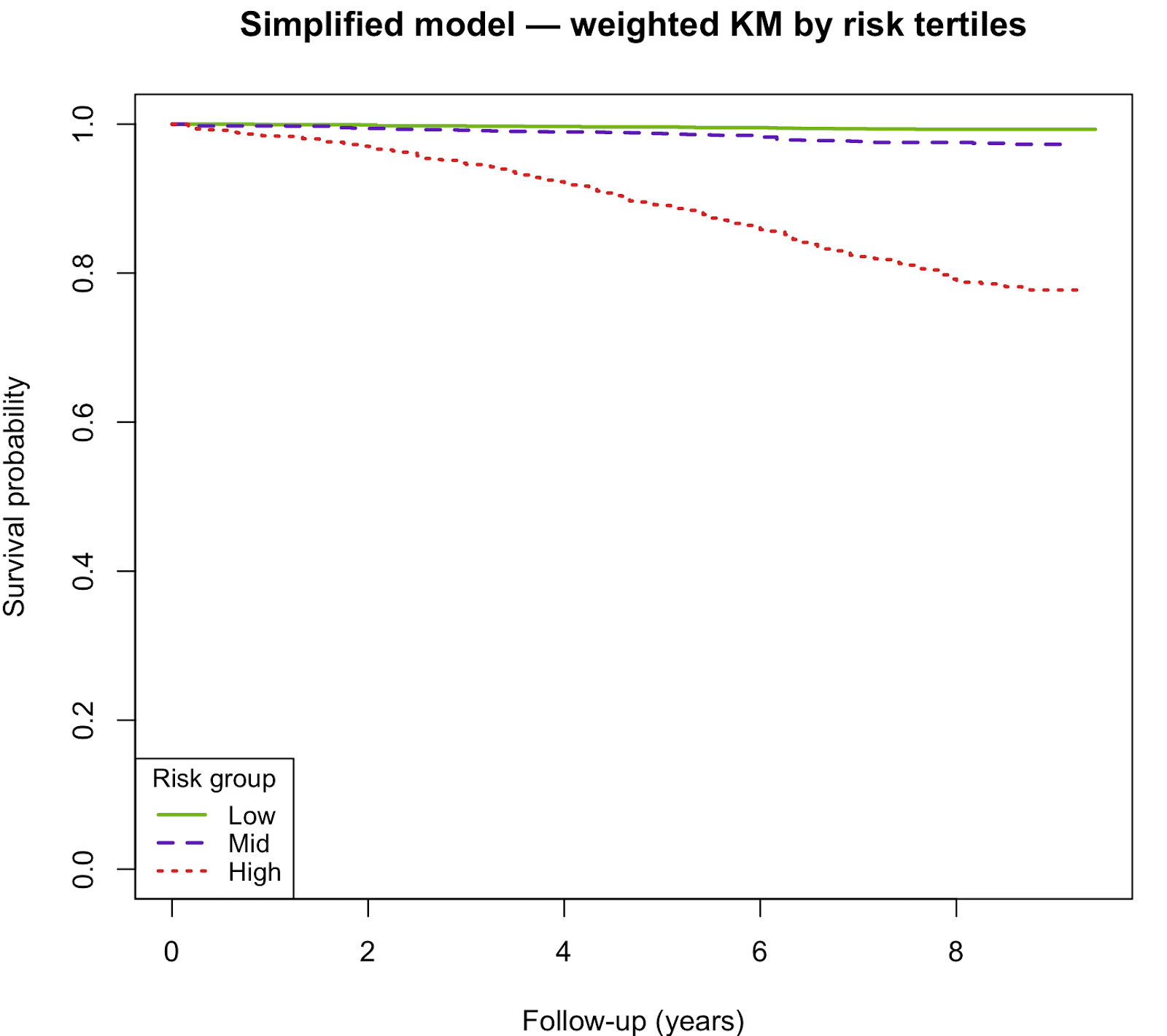
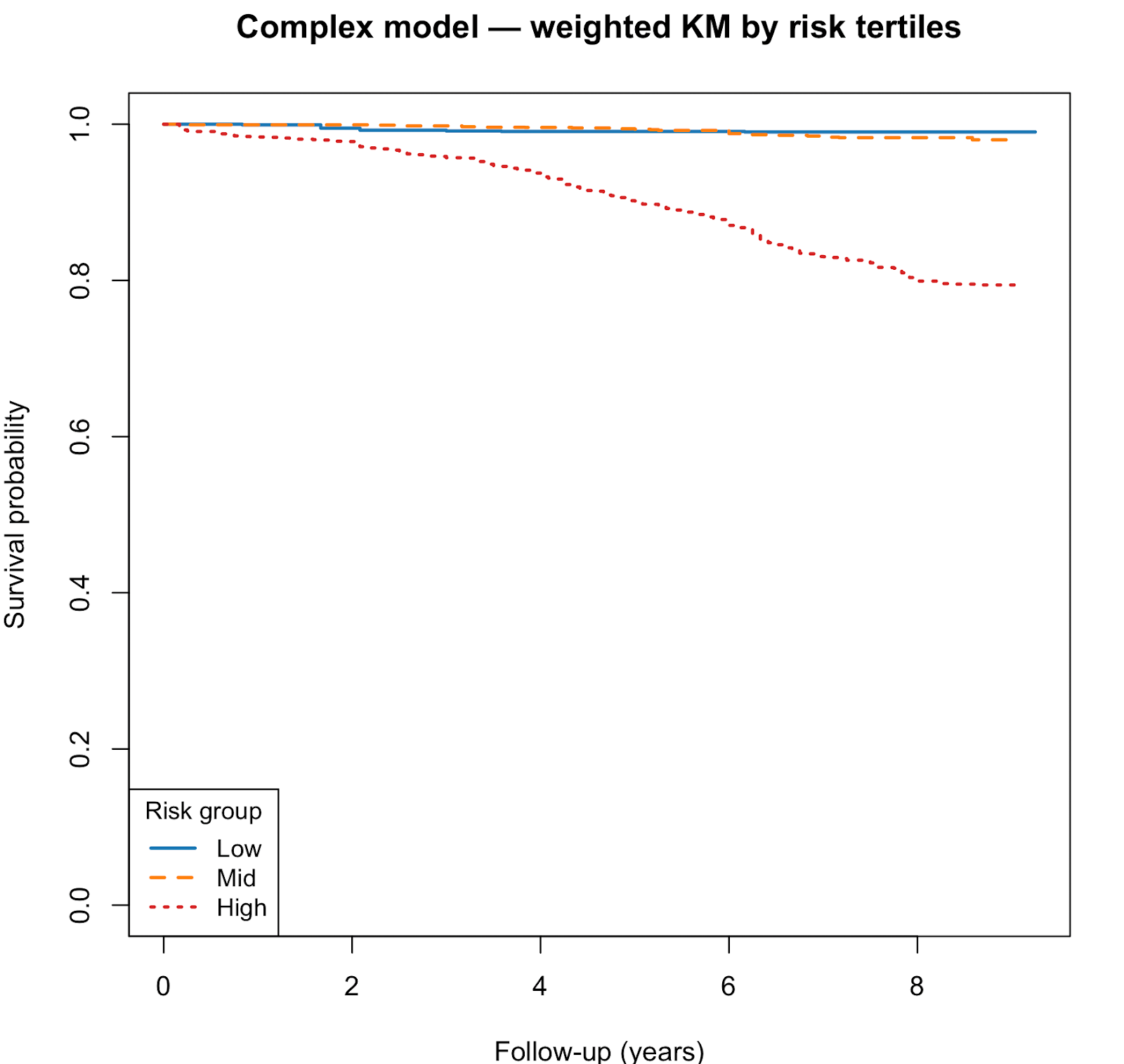
Les courbes de Kaplan-Meier ont montré une séparation nette des courbes de survie entre les tertiles de risque. Les groupes à haut risque présentaient une survie nettement inférieure à celle des groupes à risque moyen et faible.
Nous avons dérivé et validé l'âge biologique, un score de risque de mortalité transparent exprimé en termes d'âge équivalent. Les modèles simples et complexes ont tous deux démontré une excellente discrimination et un excellent calibrage (Harrell et al., 1996). Le modèle simple est parcimonieux et interprétable, tandis que le modèle complexe intègre des biomarqueurs pour une performance légèrement améliorée.
Les points forts de cette étude comprennent l'utilisation de cohortes NHANES importantes et représentatives à l'échelle nationale (2005-2009 pour l'élaboration du modèle et 2010-2011 pour la validation externe), avec des examens standardisés, des mesures de laboratoire et un lien avec la mortalité jusqu'en 2019. Les cohortes relativement récentes améliorent la pertinence par rapport aux populations contemporaines par rapport aux études plus anciennes. La disponibilité des pondérations d'enquête a permis de tirer des conclusions au niveau de la population, et notre approche analytique a intégré une modélisation spline flexible afin de saisir les associations non linéaires. Des diagnostics rigoureux du modèle (par exemple, tests de risques proportionnels, contrôles de multicolinéarité, évaluations résiduelles) et une validation externe renforcent encore la confiance dans les résultats.
Cependant, plusieurs limites doivent être prises en considération. Premièrement, des facteurs de confusion résiduels et des erreurs de mesure sont possibles, en particulier pour les expositions autodéclarées telles que le tabagisme, la consommation d'alcool et l'activité physique. Deuxièmement, notre utilisation de données complètes pour les variables de laboratoire peut introduire un biais si les données manquantes ne sont pas aléatoires, bien que la pondération de l'enquête et les analyses de sensibilité atténuent cette préoccupation ; des travaux futurs pourraient appliquer l'imputation multiple. Troisièmement, les biomarqueurs ont été mesurés à un seul moment de référence, ce qui a empêché l'évaluation des trajectoires intra-individuelles et des processus dynamiques de « rythme de vieillissement ». Quatrièmement, les risques concurrents n'ont pas été modélisés et la mortalité spécifique à une cause n'a pas été examinée. Cinquièmement, le test des risques proportionnels a suggéré une non-proportionnalité pour l'activité physique (kcal/kg/semaine, p = 0,008). Nous avons conservé cette variable sous forme linéaire pour plus de simplicité, mais reconnaissons qu'il s'agit d'une limitation susceptible d'atténuer l'estimation de l'effet au fil du temps. Sixièmement, l'utilisation de scores de risque linéaires plafonnés et la troncature pour l'ajustement des splines constituent une simplification pragmatique, mais peuvent introduire une spécification erronée du modèle ; néanmoins, les analyses de sensibilité ont confirmé la robustesse des principaux résultats.
Bien que la présente étude tire parti de l'étendue et de la représentativité de la NHANES, plusieurs domaines liés au vieillissement holistique n'ont pas pu être validés en raison de la structure des données, des limites des mesures ou de la non-signification statistique après ajustement multivarié.
L'absence ou le manque de signification doit être interprété avec prudence, compte tenu des contraintes connues du NHANES, telles que le biais d'auto-évaluation, les facteurs de confusion liés aux médicaments et la mesure ponctuelle. Nous résumons ci-dessous les principaux facteurs omis ou atténués et expliquons à la fois leur pertinence biologique et la justification de leur inclusion dans le modèle d'âge biologique Elfie afin de faciliter l'autosurveillance et la détection précoce des risques modifiables.
Architecture du sommeil (pourcentages de sommeil paradoxal et de sommeil profond)
Le NHANES enregistre la durée totale du sommeil, mais ne dispose pas des données issues de la polysomnographie sur les phases du sommeil, notamment le sommeil paradoxal et le sommeil lent (profond), qui ne sont pas disponibles dans les vagues liées à la mortalité. Des cohortes longitudinales telles que les études MrOS et Wisconsin Sleep démontrent qu'une proportion plus faible de sommeil paradoxal et une réduction du sommeil profond prédisent indépendamment la mortalité toutes causes confondues et cardiovasculaire et sont mécaniquement liées à une récupération métabolique altérée et à une neurodégénérescence (Yaffe, Laffan, Harrison, Redline et Ensrud, 2019 ; Lauderdale et al., 2020). En raison de l'absence de ces données, notre modèle n'a pas pu quantifier cette composante réparatrice du sommeil. Elfie intègre des mesures du sommeil paradoxal et du sommeil profond dérivées de dispositifs portables afin d'encourager les utilisateurs à surveiller leur récupération nocturne et à détecter la détérioration de la qualité du sommeil au fil du temps.
Variabilité de la fréquence cardiaque (VFC)
Bien que le NHANES inclue la fréquence cardiaque au repos, il ne dispose pas de l'échantillonnage ECG continu nécessaire pour calculer les indices de VRC. Une VRC réduite est un prédicteur robuste et indépendant de la mortalité cardiovasculaire et de la mortalité toutes causes confondues (Tsuji et al., 1996 ; Hillebrand et al., 2013). Elfie conserve donc la VRC comme donnée physiologique dans son application connectée à un appareil, où elle sert à la fois de marqueur de santé cardiovasculaire et d'indicateur intuitif d'auto-suivi de la résilience au stress et de l'équilibre de récupération.
Observance thérapeutique
Le NHANES recueille des informations sur les stocks de médicaments, mais ne fournit pas de données longitudinales sur l'observance. Or, une observance constante réduit considérablement la mortalité cardiovasculaire et toutes causes confondues (Simpson, Eurich, Majumdar, Padwal et Johnson, 2006). Dans Elfie, l'observance est surveillée grâce à des systèmes de suivi des renouvellements et de rappels intégrés à l'application. L'intégration de l'observance vise non seulement à améliorer la validité prédictive, mais aussi à promouvoir un engagement durable dans les routines de traitement et la détection précoce des schémas de non-observance.
Qualité alimentaire
Bien que le NHANES fournisse des rappels alimentaires sur 24 heures, il ne dispose pas d'indices longitudinaux complets tels que l'indice alternatif d'alimentation saine (AHEI-2010) pour toutes les vagues liées. La qualité de l'alimentation reste un facteur déterminant de la longévité : des scores AHEI plus élevés sont associés à une mortalité toutes causes confondues inférieure de 20 à 30 % et à une mortalité cardiovasculaire inférieure de plus de 40 % (Chiuve et al., 2012). Elfie intègre un score nutritionnel dérivé du système de profilage nutritionnel modifié de la Food Standards Agency (FSAm-NPS), conçu pour encourager l'auto-évaluation et l'amélioration progressive de l'alimentation.
Statut vaccinal
Le NHANES manque de données longitudinales cohérentes sur la vaccination dans ses cohortes liées à la mortalité. La vaccination, en particulier contre la grippe et les maladies pneumococciques, réduit les décès liés aux infections et aux maladies cardiovasculaires chez les personnes âgées (Udell et al., 2013). Au moment de cette étude, Elfie continue de développer le suivi et les rappels de vaccination dans son module de soins préventifs, encourageant ainsi une autogestion proactive de la couverture vaccinale. Les prochaines versions d'Elfie intégreront cette dimension.
Mesures cognitives et de santé mentale
Les outils validés tels que PHQ-9, GAD-7 ou EQ-5D sont absents des vagues NHANES liées, ce qui limite notre capacité à saisir le stress psychosocial et le déclin cognitif en tant que facteurs du vieillissement biologique. Les symptômes dépressifs et la mauvaise qualité de vie liée à la santé sont des prédicteurs bien établis de la morbidité et de la mortalité (Penninx et al., 2001). Les prochaines versions d'Elfie intégreront des instruments de dépistage numériques abrégés pour l'humeur, l'anxiété et le stress perçu, facilitant ainsi la détection précoce et les interventions d'autogestion de la santé.
Indice de masse corporelle (IMC)
Dans cette analyse, l'IMC n'était pas significatif après ajustement multivarié, ce qui correspond au « paradoxe de l'obésité » observé dans les cohortes plus âgées. Les mesures de l'adiposité centrale, telles que le rapport taille-hanches, sont souvent plus fortement liées à la mortalité (Zhou et al., 2021). Cependant, Elfie conserve délibérément l'IMC, ajusté en fonction de l'origine ethnique, comme indicateur principal destiné aux utilisateurs en raison de son accessibilité, de son interprétabilité et de sa valeur éducative pour promouvoir la sensibilisation au poids. Lorsque cela est possible, les utilisateurs sont encouragés à suivre leur taux de graisse corporelle plutôt que leur IMC afin de différencier les changements de masse maigre et de masse grasse, ce qui permet de fixer des objectifs réalistes et de détecter rapidement les tendances défavorables en matière de composition corporelle.
Cholestérol LDL
L'absence d'association indépendante avec le LDL reflète probablement un biais lié au traitement et à la survie ; la réduction du LDL est causalement liée à une diminution des événements athéroscléreux (Cholesterol Treatment Trialists' Collaboration, 2010). Elfie maintient le LDL comme facteur dérivé du laboratoire dans son niveau avancé afin d'améliorer la compréhension des utilisateurs en matière de risque cardiovasculaire et d'encourager la réalisation de tests lipidiques en temps opportun.
Consommation d'alcool
Aucun effet directionnel cohérent n'a été observé dans le NHANES. Des méta-analyses récentes indiquent qu'aucun niveau de consommation d'alcool ne confère un bénéfice net pour la santé (GBD 2016 Alcohol Collaborators, 2018). Elfie conserve ce facteur comportemental principalement à des fins de conscience de soi, permettant aux utilisateurs de visualiser leurs habitudes de consommation et de recevoir des commentaires motivants pour réduire leur consommation.
Fréquence cardiaque au repos
Après ajustement en fonction de l'activité physique et de la pression artérielle, la fréquence cardiaque au repos a perdu sa signification statistique. Néanmoins, une fréquence cardiaque au repos élevée reste un indicateur fiable d'un risque de mortalité accru (Zhang, Shen et Qi, 2016). Elfie intègre la fréquence cardiaque au repos mesurée par des appareils portables comme indicateur en temps réel de la condition physique, du stress et de l'état de récupération, motivant ainsi les utilisateurs à améliorer leur activité physique et leur efficacité cardiorespiratoire.
⸻
Résumé
Ces limites soulignent que le NHANES, bien qu'il soit particulièrement représentatif et précieux pour la validation, ne peut pas englober toutes les dimensions du vieillissement biologique pertinentes pour l'engagement en matière de santé préventive. Le cadre Elfie Biological Age va donc au-delà de l'ensemble de données NHANES en intégrant des mesures comportementales, physiologiques et d'adhésion spécifiquement choisies pour promouvoir l'autosurveillance, la détection précoce des facteurs de risque et l'engagement soutenu des utilisateurs dans des comportements d'amélioration de la santé que les ensembles de données épidémiologiques seuls ne peuvent pas saisir.
En traduisant des modèles de survie complexes en une échelle intuitive équivalente à l'âge, l'âge biologique offre un outil de communication puissant pour un retour d'information personnalisé sur les risques (Ganna & Ingelsson, 2015). Les cliniciens peuvent utiliser l'âge biologique pour illustrer les effets cumulatifs des facteurs de risque modifiables, fournissant ainsi un repère pertinent qui complète les estimations conventionnelles du risque absolu. Les agences de santé publique pourraient appliquer le modèle simplifié dans les milieux à faibles ressources ou dans les enquêtes démographiques où les données sur les biomarqueurs sont limitées, tandis que le modèle complet pourrait être utilisé dans des contextes cliniques ou de recherche nécessitant une plus grande précision. Une validation supplémentaire de l'âge biologique auprès de cohortes contemporaines, de populations diverses et avec des résultats de mortalité spécifiques à certaines causes sera importante pour établir sa généralisation. L'intégration dans des plateformes de santé numériques pourrait également permettre un retour d'information personnalisé en temps réel sur les risques à grande échelle.
Conceptualisation : Jean-François Legourd, Otávio Berwanger
Méthodologie : Serene Toh, Jean-François Legourd
Curation des données et analyse formelle : Serene Toh
Validation : Serene Toh
Rédaction – Ébauche originale : Serene Toh
Rédaction – Révision et édition : Otávio Berwanger, Jean-François Legourd
Supervision et contrôle scientifique : Otávio Berwanger
Financement et administration du projet : Jean-François Legourd
Tous les auteurs ont approuvé la version finale du manuscrit et acceptent d'assumer la responsabilité des travaux présentés.
Cette étude a utilisé les données accessibles au public issues de l'enquête nationale américaine sur la santé et la nutrition (NHANES) menée par les Centres pour le contrôle et la prévention des maladies (CDC).
Les données sont accessibles à l'adresse https://www.cdc.gov/nchs/nhanes/ dans le cadre d'accords d'utilisation publique ouverts.
Les données de suivi de la mortalité liées ont été obtenues auprès du Centre national des statistiques sanitaires (NCHS) à partir des fichiers publics liés à la mortalité, disponibles à l'adresse https://www.cdc.gov/nchs/data-linkage/mortality-public.htm.
Tout le code statistique utilisé pour l'estimation et la validation du modèle est disponible sur demande raisonnable adressée à l'auteur correspondant (jf@elfie.co).
Jean-François Legourd et Serene Toh sont affiliés à Elfie Inc., qui a soutenu cette étude. Les auteurs déclarent n'avoir aucun autre conflit d'intérêts.
Les auteurs ont utilisé des outils d'intelligence artificielle (OpenAI ChatGPT) pour les aider à rédiger et à réviser ce manuscrit, notamment afin d'améliorer la grammaire, la clarté et la cohérence orthographique.
De plus, des outils d'IA ont été utilisés pour générer des modèles de scripts R pour la transformation des données et la préparation des modèles liés aux analyses de risques proportionnels de Cox.
Tout le code généré par l'IA a été examiné, testé et validé par les auteurs avant d'être utilisé dans les analyses finales.
Aucun système d'IA n'a été utilisé pour la modélisation statistique autonome, l'interprétation des résultats ou la prise de décision.
Les auteurs assument l'entière responsabilité de l'intégrité, de la reproductibilité et de l'exactitude de toutes les analyses et de tous les contenus présentés.
Ce travail a été soutenu par Elfie Inc., une entreprise américaine spécialisée dans les technologies de la santé, qui intègre ce modèle sous le nom « Elfie Biological Age » (âge biologique Elfie) dans sa plateforme gratuite dédiée à la santé, accessible à des millions d'utilisateurs à travers le monde, dans le cadre de sa mission de santé publique visant à encourager l'autosurveillance.
Les auteurs remercient chaleureusement le Centre national des statistiques sanitaires (NCHS) et les Centres pour le contrôle et la prévention des maladies (CDC) des États-Unis pour avoir donné libre accès à l'Enquête nationale sur la santé et la nutrition (NHANES) et à ses fichiers liés sur la mortalité. Le programme NHANES représente un investissement public unique dans la recherche ouverte, longitudinale et riche en données sur la population, qui a permis la réalisation de milliers d'études indépendantes à travers le monde.
Nous reconnaissons que les États-Unis restent l'un des rares pays à offrir des ensembles de données aussi complets et librement accessibles sur la santé et la mortalité, ce qui favorise grandement la collaboration scientifique mondiale et accélère l'innovation méthodologique. Nous espérons que des cohortes comparables, longitudinales, diversifiées et librement accessibles verront le jour à l'échelle internationale afin d'améliorer l'inclusion, la représentativité et les progrès dans la recherche sur la santé des populations.
Benetos, A., Petrovic, M., & Strandberg, T. (2019). Hypertension management in older and frail older patients. Circulation Research, 124(7), 1045–1060. https://doi.org/10.1161/CIRCRESAHA.118.313236
Centers for Disease Control and Prevention (CDC). (2025). National Health and Nutrition Examination Survey (NHANES) : À propos du NHANES. Centre national des statistiques sanitaires. https://www.cdc.gov/nchs/nhanes/index.htm
Chiuve, S. E., Fung, T. T., Rimm, E. B., Hu, F. B., McCullough, M. L., Wang, M., Stampfer, M. J., & Willett, W. C. (2012). Indice alternatif d'alimentation saine et mortalité. The Journal of Nutrition, 142(6), 1003–1008. https://doi.org/10.3945/jn.111.157222
Cholesterol Treatment Trialists’ Collaboration. (2010). Efficacité et innocuité d'une réduction plus intensive du cholestérol LDL : méta-analyse des données issues de 170 000 participants à 26 essais randomisés. The Lancet, 376(9753), 1670–1681. https://doi.org/10.1016/S0140-6736(10)61350-5
Cox, D. R. (1972). Modèles de régression et tables de mortalité. Journal of the Royal Statistical Society: Series B (Methodological), 34(2), 187–220.
Emerging Risk Factors Collaboration. (2009). Principaux lipides, apolipoprotéines et risque de maladie vasculaire. JAMA, 302(18), 1993–2000. https://doi.org/10.1001/jama.2009.1619
Ganna, A., & Ingelsson, E. (2015). Facteurs prédictifs de mortalité à 5 ans chez 498 103 participants à la UK Biobank : une étude prospective basée sur la population. The Lancet, 386(9993), 533–540. https://doi.org/10.1016/S0140-6736(15)60175-1
Collaborateurs du GBD 2016 sur l'alcool. (2018). Consommation d'alcool et charge de morbidité dans 195 pays et territoires, 1990-2016 : une analyse systématique pour l'étude Global Burden of Disease 2016. The Lancet, 392(10152), 1015-1035. https://doi.org/10.1016/S0140-6736(18)31310-2
Goldwasser, P., & Feldman, J. (1997). Association entre l'albumine sérique et le risque de mortalité. The American Journal of Medicine, 103(6), 495–502. https://doi.org/10.1016/S0002-9343(97)00236-9
Harrell, F. E. Jr., Lee, K. L., & Mark, D. B. (1996). Multivariable prognostic models: Issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Statistics in Medicine, 15(4), 361–387. https://doi.org/10.1002/(SICI)1097-0258(19960229)15:4<361::AID-SIM168>3.0.CO;2-4
Hillebrand, S., Gast, K. B., de Mutsert, R., Swenne, C. A., Jukema, J. W., Middeldorp, S., … Dekker, J. M. (2013). Variabilité de la fréquence cardiaque et premier événement cardiovasculaire dans les populations sans maladie cardiovasculaire connue : méta-analyse et méta-régression dose-réponse. European Heart Journal, 34(38), 2679–2686. https://doi.org/10.1093/eurheartj/eht185
Klemera, P., & Doubal, S. (2006). Une nouvelle approche du concept et du calcul de l'âge biologique. Mécanismes du vieillissement et du développement, 127(3), 240–248. https://doi.org/10.1016/j.mad.2005.10.004
Levine, M. E. (2013). Modélisation du taux de vieillissement : une approche d'estimation de l'âge biologique à l'aide de multiples biomarqueurs. The Journals of Gerontology: Series A, 68(6), 667–674. https://doi.org/10.1093/gerona/gls233
Liu, Z., Kuo, P. L., Horvath, S., Crimmins, E., Ferrucci, L., & Levine, M. E. (2018). Une nouvelle mesure du vieillissement permet d'évaluer le risque de morbidité et de mortalité dans diverses sous-populations issues de l'enquête NHANES IV : une étude de cohorte. PLOS Medicine, 15(12), e1002718. https://doi.org/10.1371/journal.pmed.1002718
Loprinzi, P. D., & Cardinal, B. J. (2011). Association entre l'activité physique mesurée objectivement et le sommeil, NHANES 2005-2006. Santé mentale et activité physique, 4(2), 65-69. https://doi.org/10.1016/j.mhpa.2011.08.001
Lumley, T. (2004). Analyse d'échantillons d'enquêtes complexes. Journal of Statistical Software, 9(1), 1–19. https://doi.org/10.18637/jss.v009.i08
Lumley, T. (2023). survey : Analyse d'échantillons d'enquêtes complexes (package R version 4.3.2). https://CRAN.R-project.org/package=survey
Myers, J., Prakash, M., Froelicher, V., Do, D., Partington, S., & Atwood, J. E. (2002). Capacité physique et mortalité chez les hommes orientés vers des tests d'effort. The New England Journal of Medicine, 346(11), 793–801. https://doi.org/10.1056/NEJMoa011858
Penninx, B. W. J. H., Guralnik, J. M., Mendes de Leon, C. F., Pahor, M., Visser, M., Corti, M. C., Wallace, R. B., & Berkman, L. F. (2001). Événements cardiovasculaires et mortalité chez les hommes et les femmes âgés dépressifs : une étude prospective menée au sein de la communauté. Archives of General Psychiatry, 58(3), 221–227. https://doi.org/10.1001/archpsyc.58.3.221
Équipe centrale R. (2024). R : langage et environnement pour le calcul statistique. Fondation R pour le calcul statistique. https://www.R-project.org/
Rehm, J., Gmel, G., Gmel, G., et al. (2017). La relation entre les différentes dimensions de la consommation d'alcool et le fardeau de la maladie : aperçu général. Addiction, 112(1), 101–107. https://doi.org/10.1111/add.13455
Royston, P., & Sauerbrei, W. (2007). Multivariable model-building: A pragmatic approach to regression analysis based on fractional polynomials for modelling continuous variables. Wiley. https://doi.org/10.1002/9780470722184
Simpson, S. H., Eurich, D. T., Majumdar, S. R., Padwal, R. S., & Johnson, J. A. (2006). Une méta-analyse de l'association entre l'observance d'un traitement médicamenteux et la mortalité. JAMA, 296(21), 2643–2653. https://doi.org/10.1001/jama.296.21.2643
Therneau, T. M., & Grambsch, P. M. (2000). Modélisation des données de survie : extension du modèle de Cox. Springer-Verlag. https://doi.org/10.1007/978-1-4757-3294-8
Tsuji, H., Venditti, F. J., Manders, E. S., Evans, J. C., Larson, M. G., Feldman, C. L., & Levy, D. (1996). Réduction de la variabilité de la fréquence cardiaque et du risque de mortalité dans une cohorte de personnes âgées. Circulation, 94(11), 2850–2855. https://doi.org/10.1161/01.CIR.94.11.2850
Udell, J. A., Zawi, R., Bhatt, D. L., Keshtkar-Jahromi, M., Gaughran, F., Phrommintikul, A., … Cannon, C. P. (2013). Association entre la vaccination contre la grippe et les résultats cardiovasculaires chez les patients à haut risque : une méta-analyse. JAMA, 310(16), 1711–1720. https://doi.org/10.1001/jama.2013.279206
Wood, S. N. (2017). Modèles additifs généralisés : une introduction avec R (2e éd.). CRC Press. https://doi.org/10.1201/9781315370279
Yaffe, K., Laffan, A. M., Harrison, S. L., Redline, S., & Ensrud, K. E. (2019). Troubles respiratoires du sommeil, hypoxie et risque de troubles cognitifs légers et de démence chez les femmes âgées. JAMA Neurology, 76(6), 653–660. https://doi.org/10.1001/jamaneurol.2018.4719
Zhang, D., Shen, X., & Qi, X. (2016). Fréquence cardiaque au repos et mortalité toutes causes confondues et cardiovasculaire dans la population générale : une méta-analyse. Heart, 102(8), 701–708. https://doi.org/10.1136/heartjnl-2015-308963
Zhou, B., Carrillo-Larco, R. M., Danaei, G., Riley, L. M., Paciorek, C. J., Stevens, G. A., … Ezzati, M. (2021). Tendances mondiales en matière d'indice de masse corporelle, d'insuffisance pondérale, de surpoids et d'obésité de 1975 à 2016 : analyse groupée de 2 416 études de mesure basées sur la population. JAMA Network Open, 4(9), e2128938. https://doi.org/10.1001/jamanetworkopen.2021.28938
Caractéristiques de base pondérées
Tableau S1 : Variables continues et binaires pour le modèle simple avec NHANES 2005-2009
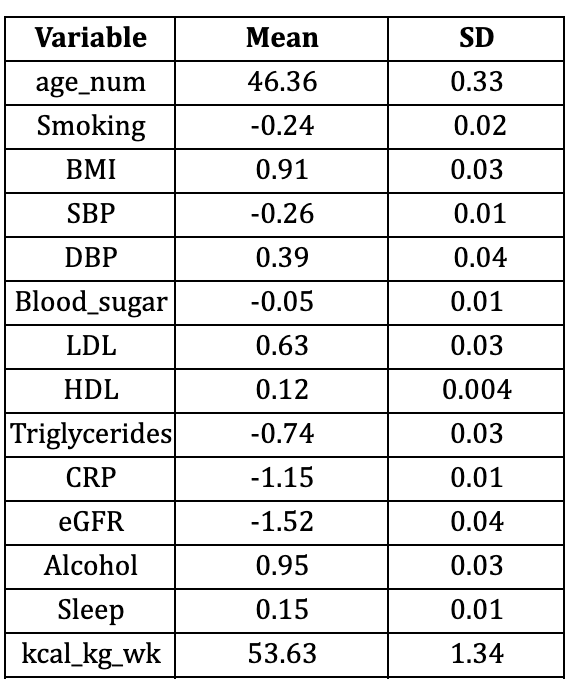
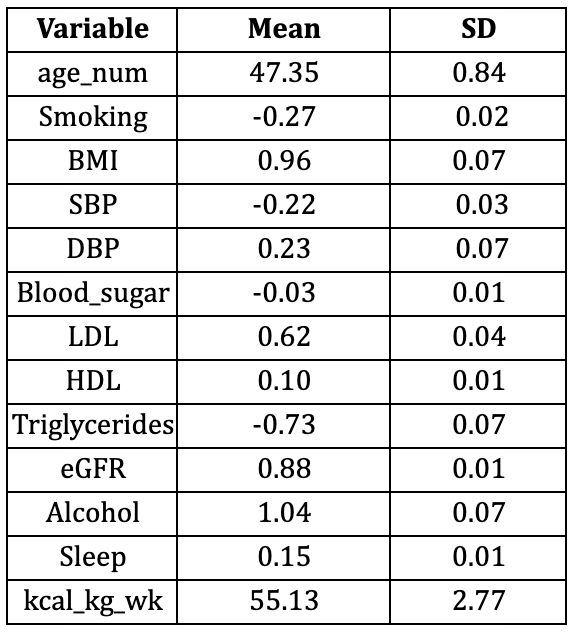
Tableau S2 : Variables continues et binaires pour le modèle simple avec NHANES 2010-2011
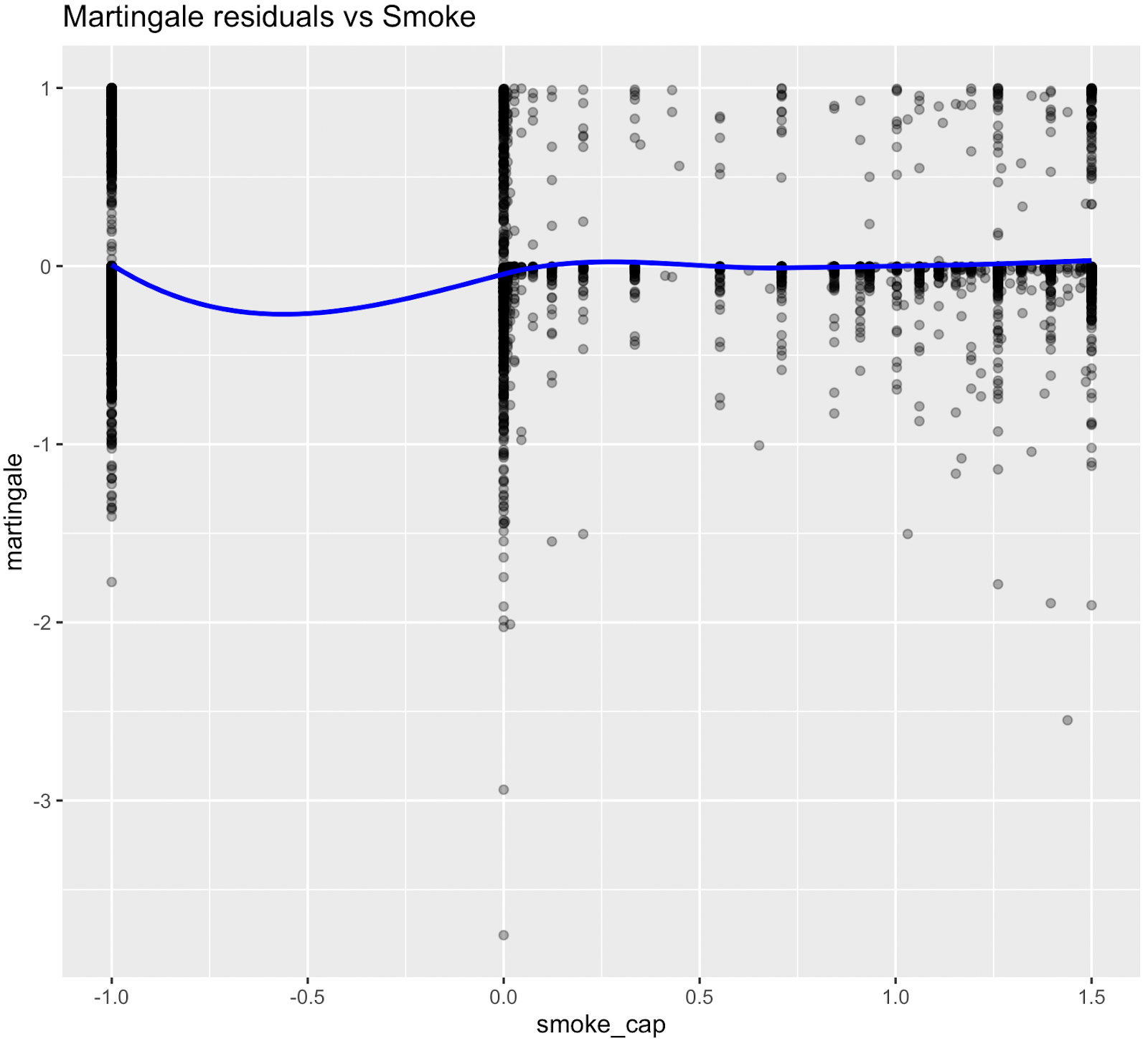
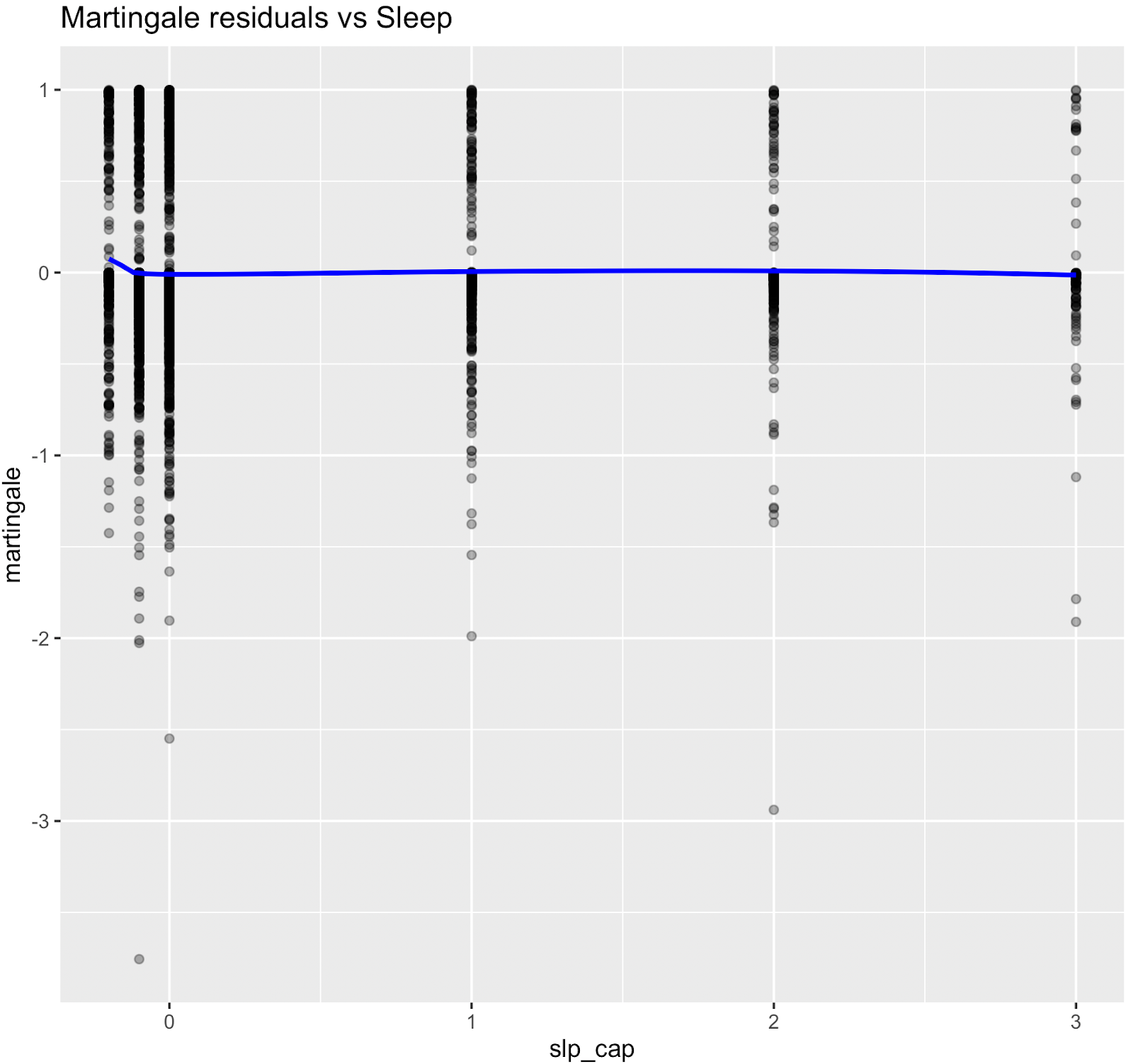
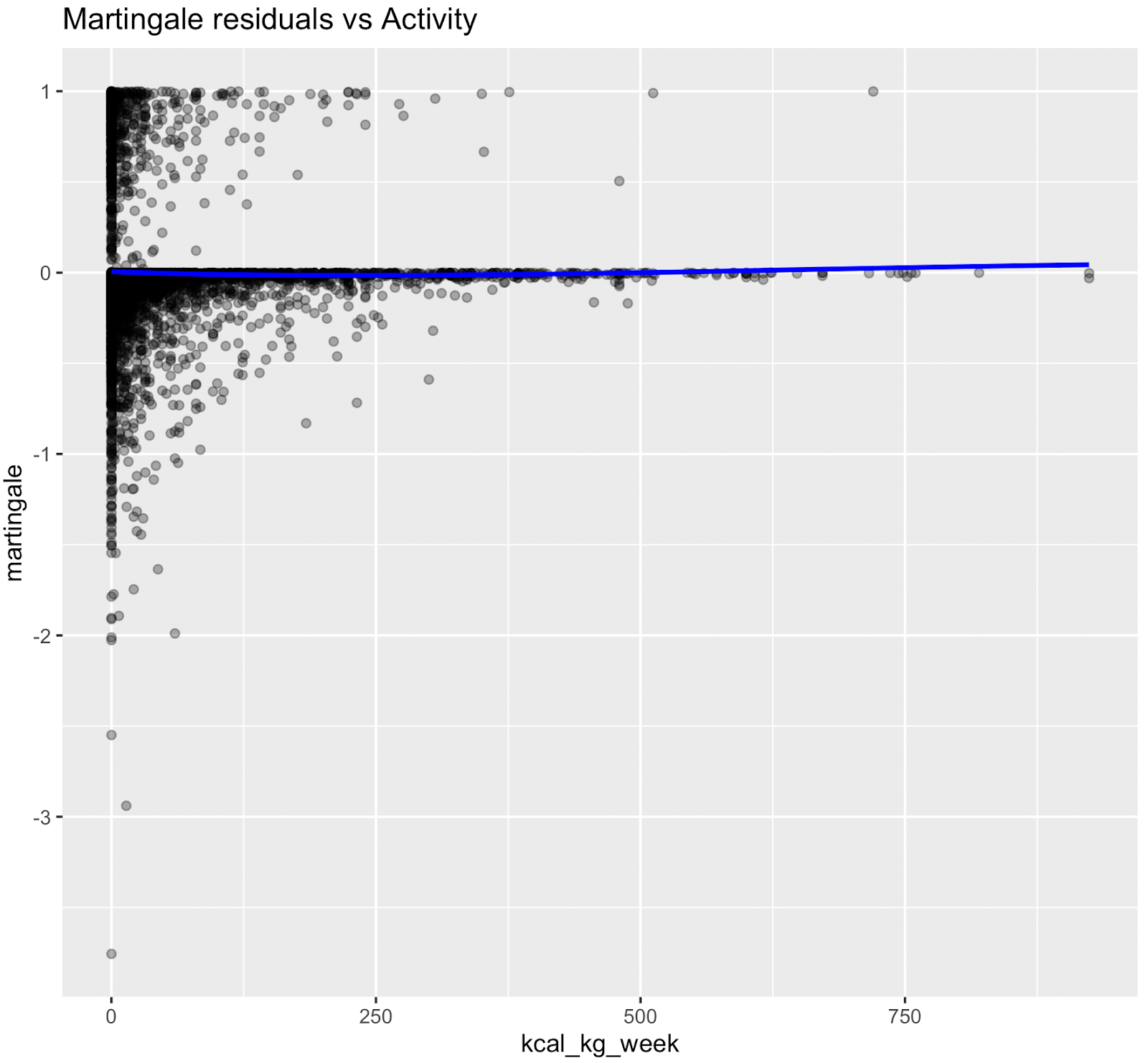
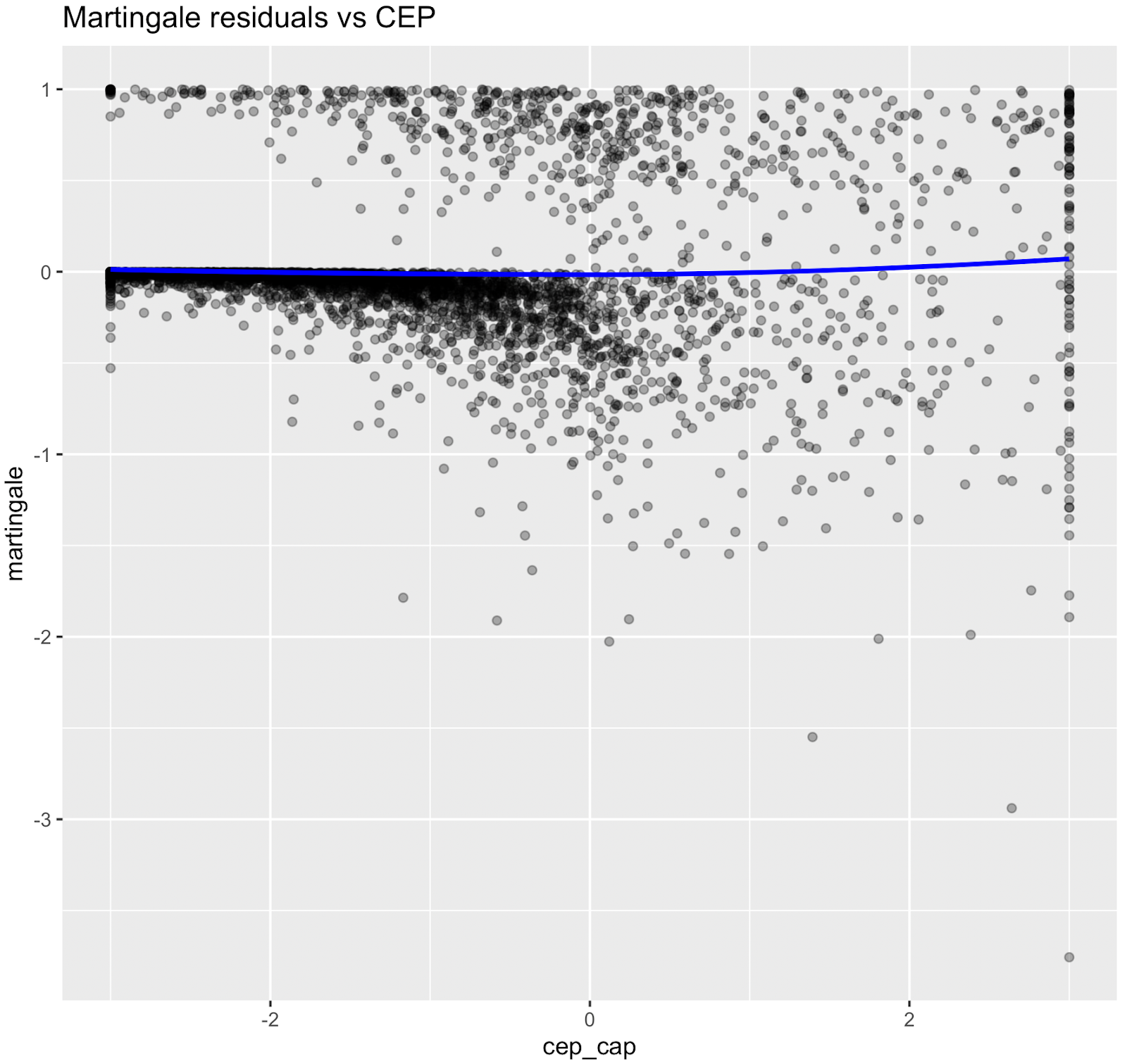
Les résidus de Martingale ont indiqué que les termes linéaires étaient adéquats pour le tabagisme, les heures de sommeil, la dépense métabolique totale, le DFG estimé et la pression artérielle systolique, tandis que la glycémie présentait une non-linéarité évidente, ce qui justifie l'utilisation de fonctions splines pour ces variables dans le modèle final.
Formule principale
Âge biologique = ChronoAge + Delta
où :
• ChronoAge : âge chronologique
• Delta = ∑ (βi*zi*fi) / βage
• βi : impact de l'âge du facteur i ;
• zi : valeur normalisée du facteur i ; écrêtée [−3,+3] pour supprimer les valeurs aberrantes
• fi : fraîcheur du facteur i ; fi∈[0,1] (1 = entièrement frais, 0 = trop périmé)
• Delta maintenu entre [−12,+12] ans pour protéger la crédibilité : si | Σ(βi * zi * fi) | > 12, recalculer avec BioAge = Age + Σ(εi * zi * fi)/βage, où εi = βi * ( 12 / | Σ(βi * zi * fi) | ) ;
• Calculé uniquement s'il existe au moins 3 facteurs dont fi > 50 %.
Le niveau de précision de l'âge biologique dépend des facteurs de fraîcheur (fi).
Précision = moyenne (fi) * min ( count(fi>0) / 5, 1 )
où :
• Une précision de 100 % nécessite au moins 5 facteurs récents.

